RISC-V Blog Series Introduction¶
[Omitted long matching line]I don’t need to take into the account all the requirements from the start in order to design the architecture before I start the implementation. This means that I will sooner start the implementation and have feedback about my architectural choices and thus avoid catching architectural errors late, which are then most expensive to fix.
I can get an MVP (Minimum Viable Product) early, which means that I can start system testing early and try to catch errors in the design’s functional requirements as early as possible.
I can maintain my MVP, so that the customer can try to use the hardware at different stages throughout the development. This offers him a chance to shorten the time-to-market and may provide me with the valuable feedback. This can again lead to the change to the requirements which I would like to have as early as possible.
“Hardware” and “requirements change” are two things that were not meant to go together, but the electronics industry is developing at an ever accelerating pace so this needs to change. This is also recognized by the very authors of the RISC-V ISA, and summed up in their paper AN AGILE APPROACH TO BUILDING RISC-V MICROPROCESSORS.
Why PyGears?¶
Traditional HDLs and design methodologies built around them are ill-suited for building larger hardware systems, because they offer very few means of abstraction, besides grouping the implementation into modules. Modules are furthermore quite often formed in the wrong way, by bundling various functionalities together because they operate on the same data, even though they serve different purposes. Think big clunky control path state machines with many outputs which are usually the major source of bugs and a major obstacle for adding new features.
Image from <http://ece-research.unm.edu/jimp/codesign/slides/microprogramming.pdf>¶
Each of these outputs is probably computed by a functionality that deserves its own module, its own little abstraction. Why are they than being sucked into state machine module monsters? Usually because we either believe that it leads to a more optimized design, or we are afraid of synchronization issues. But wire is a wire even if it leaves the module boundaries, and decent hardware synthesis tools offer inter-module optimization, so we lose next to nothing by factoring out the functionality. As for the synchronization, putting everything in a single module just offers a false sense of security and sweeps the problem under the rug until later when functionality piles up inside the module and pipelining becomes a nightmare, not to mention dealing with synchronization issues between such complex modules.
[Omitted long matching line]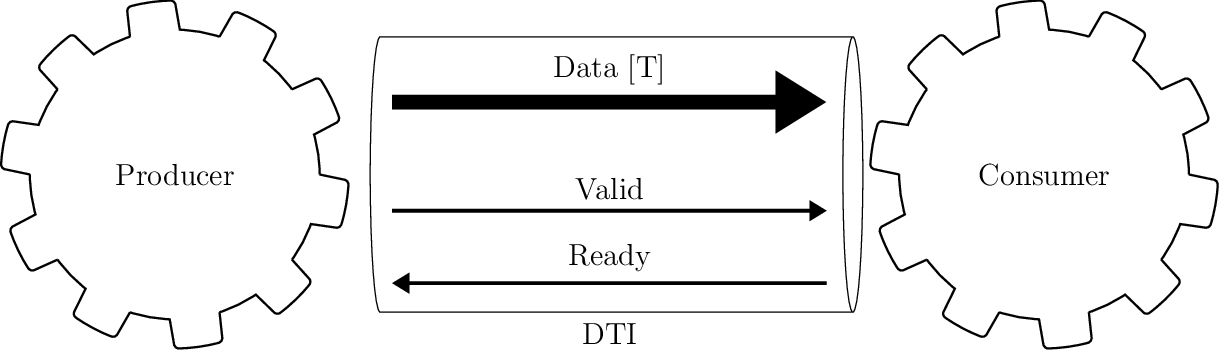
DTI - Data Transfer Interface
[Omitted long line with 2 matches]
Paradigm shift the PyGears framework offers over traditional HDLs is analog to the difference in paradigm between OOP (Object Oriented Programming) and Functional programming. In OOP, you program in terms of objects, which are in turn formed to enclose certain state and provide operations that depend on that state and can change it. This is very similar to how HDL modules are formed, as discussed earlier in this chapter. On the other hand, in functional programming, you program in terms of functions and types of the data passed between them, which is exactly how you describe hardware with PyGears. It is widely considered that parallel software designs are easier described using functional programming paradigm, so my aim is to show in this blog series that the same holds for the hardware design.
Furthermore, PyGears is written in Python and offers a way to run RTL simulation together with asynchronous Python functions, in which arbitrary functionality for stimulus generation, value checking, logging and gathering statistics. Some advantages over SystemVerilog are that Python is open-sourced, much more popular, has huge library of packages and has cleaner syntax.
Why not some of the existing modern HDLs?¶
I am aware of several other attempts at higher level HDLs, like: Chisel, Bluespec, Clash and MyHDL. I never dug deeper into these languages, so I’m not able to give an in depth analysis of each of them here. It’s not that I don’t plan to learn them better sometimes, as I’m sure they have many brilliant ideas incorporated, it’s just that they didn’t seem to really offer solutions to the problems discussed in the previous chapter. Even Clash, which takes the functional approach, in my opinion missed the opportunity to really raise the level of abstraction, by still dealing with the individual signals (as opposed to the flow-controlled interfaces in PyGears) and thus significantly lowering the composability of the modules. Other languages mentioned here take state-centric path of the traditional HDLs and so I truly feel that PyGears has to offer something better.
Writing tests as a design tool¶
Usually the hardware implementation effort is split between the design and verification teams, where the design team leaves all the testing to the verification. I think that this is a bad dichotomy and tend to agree with the TDD (Test-Driven Development) philosophy which points-out the importance of the developers tests. These are the tests written by the designers continuously during the development, which test each of the functional requirements of the design.
According to the TDD, the implementation of each functional requirement should be performed in three steps: red, green and refactor:
Red: Add tests to verify the functional requirement. Run the tests to check that they fail, which they ought to do since the functionality hasn’t been implemented yet.
Green: Work on the functionality implementation until all the tests pass (new ones as well as the ones testing previously implemented requirements).
Refactor: Clean-up the code without breaking the tests
For the RISC-V implementation, I plan on treating each instruction in the ISA as a separate functional requirement, so I should have a following flow:
Write a test that feeds the instruction to the processor and checks the memory and register state after the execution against the Spike RISC-V ISA simulator (which will serve as a reference model),
Implement the instruction in hardware and verify that the test passes together with all the tests for the previously implemented instructions,
Refactor the processor implementation.
Besides functional correctness, one additional important processor design quality parameter is its throughput. So, in addition to the functional tests for each of the instructions, I plan to use Vivado to test attainable frequency for my design.
Even though I’m aware of the already proposed architectures for the RISC-V processor (like the one in the Computer Architecture: A Quantitative Approach), I will try to blank out the memory of them, and let the new one, guided by the PyGears principles, arise on its own.
Setup¶
[Omitted long matching line]PyGears,
An RTL simulator: I’ll be using mostly Verilator since it is open-source, but I will try to provide an option in the code to run Questa or Cadence simulators as well,
A waveform viewer: I’ll be using GtkWave since again it is open-source, but if you plan on using a proprietary simulator, they will come with a waveform viewer,
A constrained random solver: I’ll try to use SCV. Again proprietary simulators have support for this too,
Various RISC-V tools, for which I will make further posts on how to setup and use.
I’ll be using Spacemacs for editing files and running Python scripts, but I’ll try to test the procedures I layout in blog posts on PyCharm as well.
Logistics¶
All the files related to the RISC-V implementation will be pyblished inside pygears_riscv git repository. At the beginning of each blog post, I will state which exact git commit contains code relevant to that post, so that you can get back in history and inspect files at that development stage. Before you can run the scripts from the pygears_riscv repository, you need to set it up:
git clone https://github.com/bogdanvuk/pygears_riscv.git
cd pygears_riscv
python setup.py develop
Notice also a slider at the beginning of the post. It allows you to choose the verbosity of the text. I plan to use it for all future posts in a fashion similar to this:
Verbosity level 1: Only as much information as needed to reproduce the results the post is discussing,
Verbosity level 2: Additional details and explanations about each of the steps involved in the discussed procedure,
Verbosity level 3: Various digressions, brain dumps, detailed results of the procedure steps (log files, command outputs), etc.